
데이터베이스의 규모 확장
저장할 데이터가 많아지면 데이터베이스에 대한 부하도 증가하게 된다. 그때가 오면 데이터베이스를 증설할 방법을 찾아야 한다. 데이터베이스의 규모를 확장하는 데는 두 가지 접근법이 있다.
📄 수직적 확장
Scale-up 이라고도 부르는 수직적 규모 확장법은 기존 서버에 더 많은, 또는 고성능의 자원(CPU, RAM, 디스크 등)을 증설하는 방법이다. 이러한 수직적 접근법에는 몇 가지 심각한 약점이 있다.
- 데이터베이스 서버 하드웨어에는 한계가 있으므로 CPU, RAM 등을 무한 증설할 수는 없다. 사용자가 계속 늘어나면 한대 서버로는 결국 감당하기 어렵게 될 것이다.
- SPOF(Single Point of Failure)로 인한 위험성이 크다.
- 비용이 많이 든다. 고성능 서버로 갈수록 가격이 올라가는 것은 당연하다.
📄 수평적 확장
데이터베이스의 수평적 확장은 샤딩(sharding)이라고도 부르는데, 더 많은 서버를 추가함으로써 성능을 향상시킬 수 있다. 아래 그림은 수직적 확장법과 수평적 확장법이 어떻게 다른지 보여준다.

Sharding / Shard
샤딩은 대규모 데이터베이스를 샤드(shard)라고 부르는 작은 단위로 분할하는 기술을 말한다. 즉, 데이터베이스에서 부하 분산을 위해 다수의 데이터베이스에 데이터를 분산 저장하는 기법이다. 모든 샤드는 같은 스키마를 쓰지만 샤드에 보관되는 데이터 사이에는 중복이 없다.
샤딩의 장점
- Scale-Out이 가능
- 스캔 범위를 줄여서 쿼리 반응 속도를 빠르게 함
- 장애가 샤드 단위로 발생함
샤딩의 단점
- 프로그래밍의 복잡도가 증가
- 데이터가 한 쪽 샤드로 몰릴 경우(Hotspot), 샤딩이 무의미 해짐
- 잘 못 사용할 경우 risk가 큼
- 한번 샤딩 사용시 샤딩 이전의 구조로 돌아가기 힘듬
샤딩의 문제점
- 조인과 비정규화 : 일단 하나의 데이터베이스를 여러 샤드 서버로 쪼개고 나면, 여러 샤드에 걸친 데이터를 조인하기가 힘들어진다. 이를 해결하는 한 가지 방법은 데이터베이스를 비정규화하여 하나의 테이블에서 질의가 수행될 수 있도록 하는 것이다.
- 샤드 간의 데이터 분포가 균등하지 못하여 어떤 샤드에 할당된 공간 소모가 다른 샤드에 비해 빨리 진행될 때
이 경우를 샤드 소진(shard exhaustion)이라고도 부르는데 이런 현상이 발생하면 샤드 키를 계산하는 함수를 변경하고 데이터를 재배치하여야 한다. 안정 해시(consistent hashing) 기법을 활용하면 이 문제를 해결할 수 있다.
Sharding 의 종류
1. 모듈러 샤딩 (Modular Sharding)
모듈러 샤딩은 PK를 모듈러 연산한 결과로 DB를 라우팅하는 방식으로
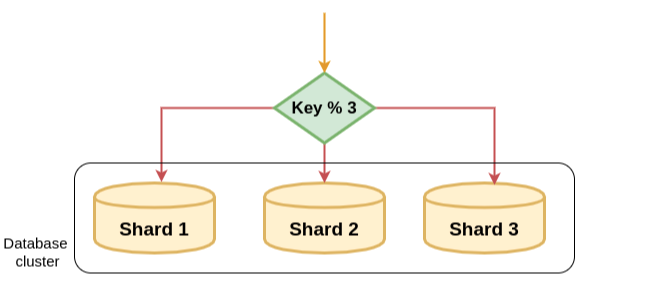
- 레인지 샤딩에 비해 데이터가 균일하게 분산된다.
- DB를 추가 증설하는 과정에서 이미지 적재된 데이터의 재정렬이 필요하다.
- 데이터가 일정 수준에서 예상되는 데이터 성격을 가진곳에 적용할 때 어울린다.
2. 레인지 샤딩 (Range Sharding)
레인지 샤딩은 PK의 범위를 기준으로 DB를 특정하는 방식으로

- 모듈러 샤딩에 비해 기본적으로 증설에 재정렬 비용이 들지 않는다.
- 일부 DB에 데이터가 몰릴 수 있다.
다만 활성 유저가 몰린 DB로 트래픽이나 데이터량이 몰릴 수 있다.(=hotspot key) 그러면 또 몰리는 DB는 분산시키고 트래픽이 저조한 DB는 통합시키는 과정이 필요하다. 따라서 적절한 Range 기준을 잡는 것이 중요하다.
3. 디렉토리 샤딩 (Directory Sharding)
디렉토리 샤딩은 별도의 조회 테이블을 사용해서 샤딩을 하는 경우로

- 샤딩에 사용되는 시스템이나 알고리즘을 사용할 수 있다.
- 샤드를 동적으로 추가하는 것도 비교적 쉽다.
- 모든 읽기 및 쓰기 쿼리 전에 조회 테이블을 참조해야 하므로 오버헤드가 발생한다.
샤딩 키 (Sharding Key)
샤딩 전략을 구현할 때 고려해야 할 가장 중요한 것이 바로 샤딩 키(sharding key)를 어떻게 정하느냐 하는 것이다. 샤딩 키는 파티션 키(partition key)라고도 부르는데, 데이터가 어떻게 분산될지 정하는 하나 이상의 칼럼으로 구성된다. 샤딩 키를 통해 올바른 데이터베이스에 질의를 보내어 데이터 조회나 변경을 처리하므로 효율을 높일 수 있다. 이 샤딩 키를 정할 때는 데이터를 고르게 분할 할 수 있도록 하는 게 가장 중요하다.
출처
- https://trillium.tistory.com/128
'아키텍쳐 (Architecture)' 카테고리의 다른 글
| Spring Web 패키지 구조 (계층형 구조 / 도메인 구조) (0) | 2024.04.10 |
|---|---|
| 로드밸런서 (Load Balancer)란 ? (0) | 2024.01.19 |