
Collections Framework
컬렉션즈 프래임워크라는 것은 다른 말로는 컨테이너라고도 부른다. 즉 값을 담는 그릇이라는 의미이다. 그런데 그 값의 성격에 따라서 컨테이너의 성격이 조금씩 달라진다. 자바에서는 다양한 상황에서 사용할 수 있는 다양한 컨테이너를 제공하는데 이것을 컬렉션즈 프래임워크라고 부른다. 전에 배운 ArrayList는 그중의 하나다.
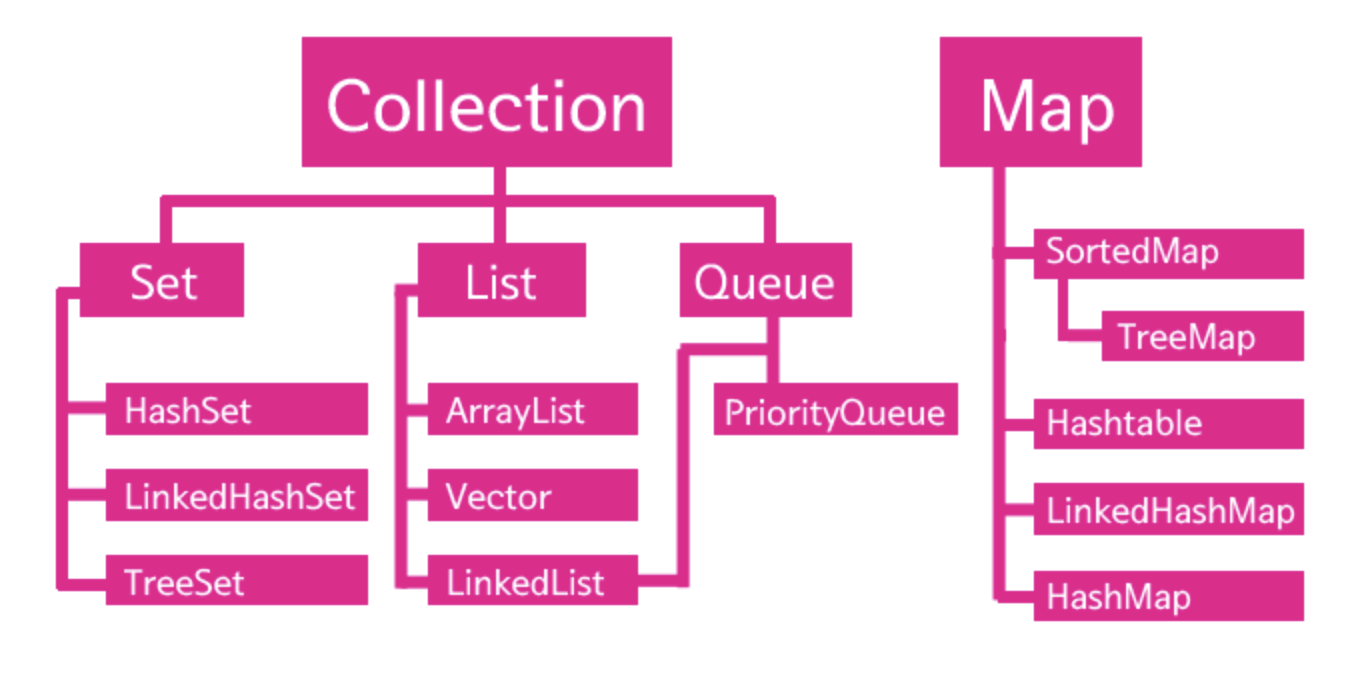
Collection과 Map이라는 최상위 카테고리가 있고, 그 아래에 다양한 컬렉션들이 존재한다. ArrayList는 LIst라는 성격으로 분류되고 있는 것이다. List는 인터페이스이다. 그리고 List 하위의 클래스들은 모두 List 인터페이스를 구현하기 때문에 모두 같은 API를 가지고 있다. 클래스의 취지에 따라서 구현방법과 동작방법은 다르지만 공통의 조작방법을 가지고 있는 것이다. List와 Set의 차이점은 List는 중복을 허용하고, Set은 허용하지 않는다. 그리고 순서가 보장되냐 되지않느냐 이다.
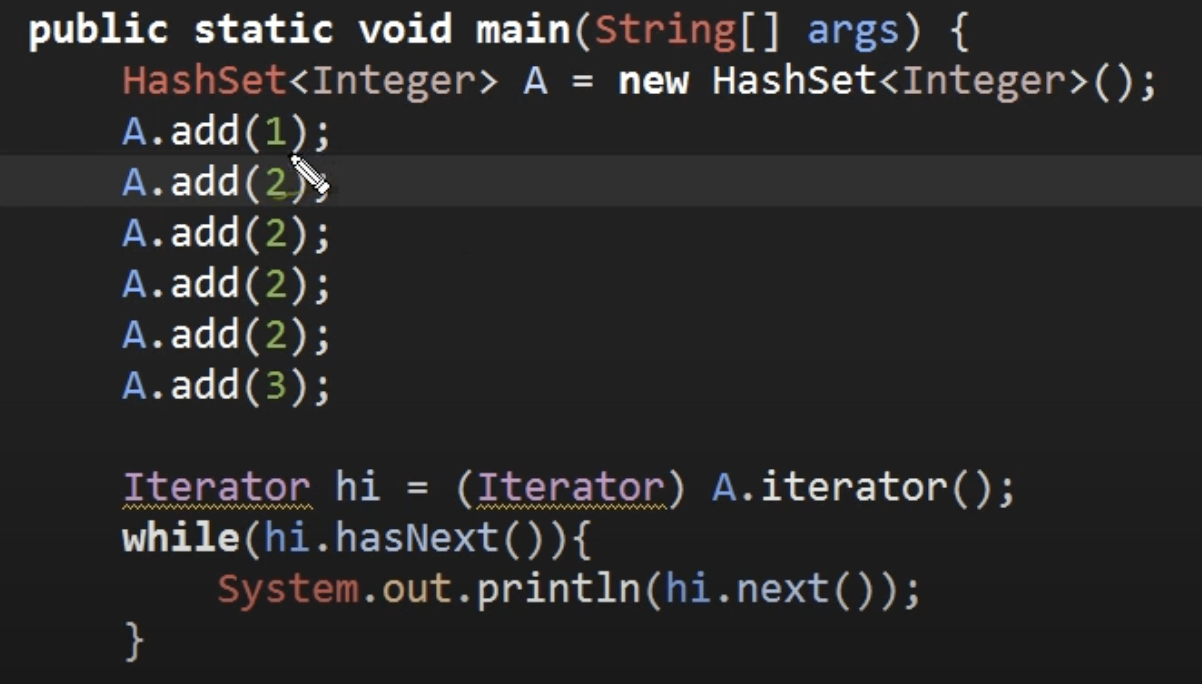
위의 HashSet의 출력값은 1,2,3 이다. 중복되는 값은 추가되지 않고 고유한 값들만이 저장되는 특성이다.
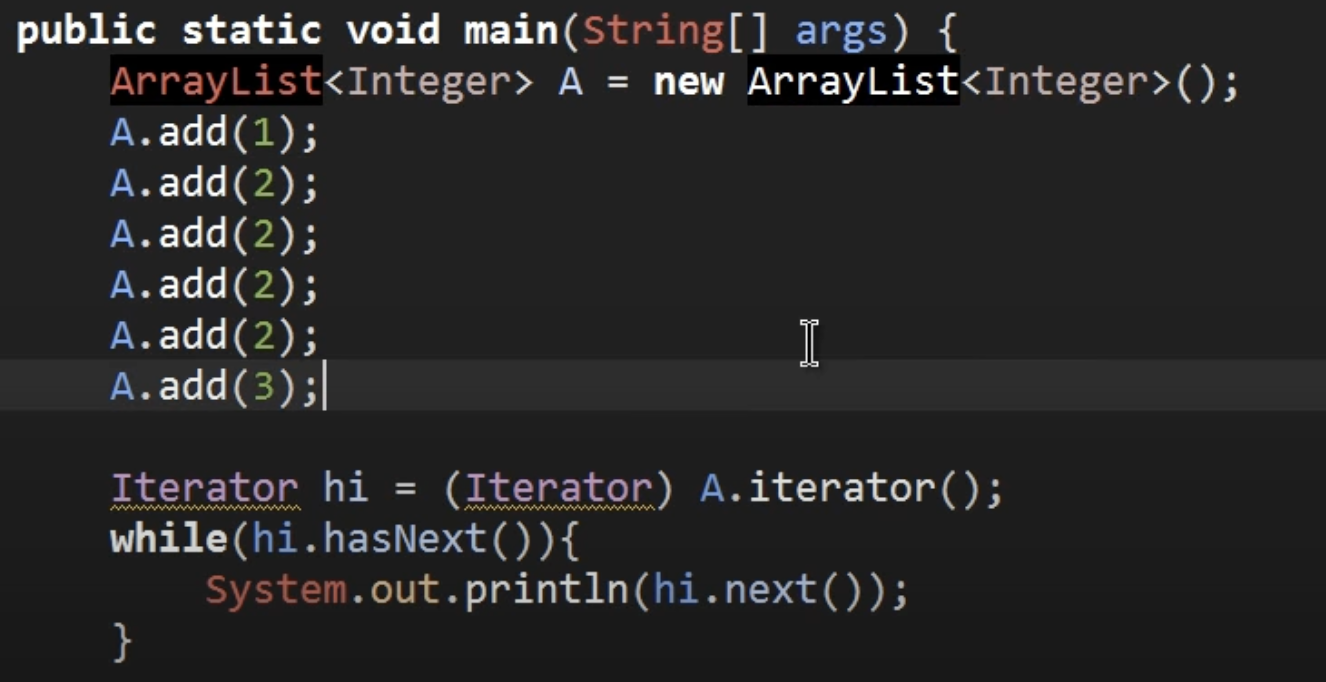
위의 출력값은 1,2,2,2,2,3 그대로 출력된다. 사용자가 추가하는 모든값이 추가가 된다는 의미이다. 위의 결과를 통해서 알 수 있는 것처럼 Set는 중복을 허용하지 않고 순서가 없지만, List는 중복을 허용하고 저장되는 순서가 유지된다는 것을 알 수 있다. 이러한 특징을 고려해서 컬렉션을 선택해야 한다.
A - { 1, 2, 3 }
B - { 3, 4, 5 }
C - { 1, 2 }
라는 집합으로 가정할 때
부분집합 (subset)
A.containsAll(B); 는 false - B는 A의 부분집합이 아니다.
A.containsAll(C); 는 ture - C는 A의 부분집합이다.
합집합(union)
A.addAll(B); 의 출력값은 1, 2, 3, 4, 5 이다.
교집합(intersect)
A.retainAll(B); 의 출력값은 3 이다.
차집합(difference)
A.removeAll(B); 의 출력값은 1, 2이다.
(SET = 집합, 중학교때 배운 집합을 생각하면 편하다. 각각의 고유한 원소들로만 이루어져 있는 집합 - 합집합,교집합,부분집합 등 집합의 수학적 정의와 같다)
* 집합에는 순서가 보장되지 않는다
Iterator
위에 나온 Iterator에 대해서 알아보면

이러한 기능을 조합하면 for 문을 이용하는 것과 동일하게 데이터를 순차적으로 처리할 수 있다.
ai라는 iterator 데이터 타입의 가상의 집합을 만들어 hasNexts는 ai안의 값들이 존재하는지 확인한다. -> true
next -> 그 안의 값중에 하나를 리턴한다 (iterator 안의 리턴한 값은 사라진다. ai안의 값이 사라지는 것이지 원래 데이터에는 무관하다.)
-> 다시 while 문으로 돌아간다.
메소드 iterator는 인터페이스 Collection에 정의되어 있다. 따라서 Collection을 구현하고 있는 모든 컬렉션즈 프레임워크는 이 메소드를 구현하고 있음을 보증한다. 메소드 iterator의 호출 결과는 인터페이스 iterator를 구현한 객체를 리턴한다. 인터페이스 iterator는 아래의 메소드를 구현하도록 강제하고 있는데 각각의 역할은 아래와 같다.
- hasNext : 반복할 데이터가 더 있으면 true, 더 이상 반복할 데이터가 없으면 false를 리턴한다.
- next : hasNext가 true라는 것은 next가 리턴할 데이터가 존재한다는 의미이다.
Map
Map 컬렉션은 key와 value의 쌍으로 값을 저장하는 컬렉션이다. 밑에는 맵을 구현하는 방식이다.

Map에서 데이터를 추가할 때 사용하는 API는 put이다. put의 첫번째 인자는 값의 key이고, 두번째 인자는 key에대한 값이다. key를 이용해서 값을 가져올 수 있다.

메소드 entrySet은 Map의 데이터를 담고 있는 Set을 반환한다. 반환한 Set의 값이 사용할 데이터 타입은 Map.Entry이다. Map.Entry는 인터페이스인데 아래와 같은 API를 가지고 있다. 이것을 이용해서 Map의 key,value를 조회할 수 있다.
- getKey
- getValue
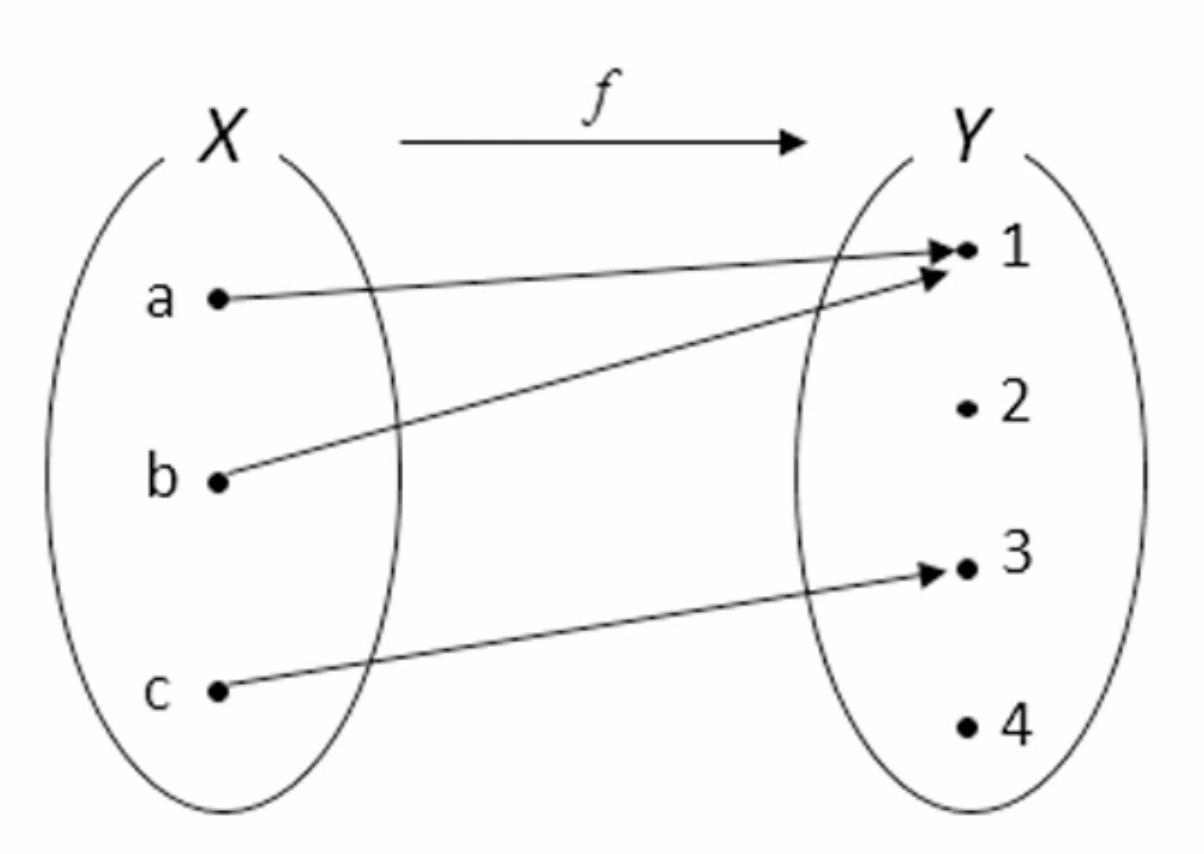
x의값은 중복이 허용되지 않지만 y의 값은 중복이 허용된다. 이처럼 함수의 정의역, 공역, 치역과 같은 개념이라고 할 수 있다.
앞서 Set이 수학의 집합을 프로그래밍적으로 구현한 것이라고 언급했다. map은 수학의 함수를 프로그래밍화한 것이다. 수학의 함수가 "정의역과 공역 원소들 사이의 단가 대응의 관계"라는 의미를 이해하고 있는 사람이라면 Map의 key와 value의 관계가 함수의 정의역과 공역의 관계와 같다는 것을 이해할 수 있을 것이다.
Collections
컬렉션을 사용하는 이유 중의 하나는 정렬과 같은 데이터와 관련된 작업을 하기 위해서다. 정렬하는 법을 알아보자. 패키지 java.util 내에는 Collections 라는 클래스가 있다.
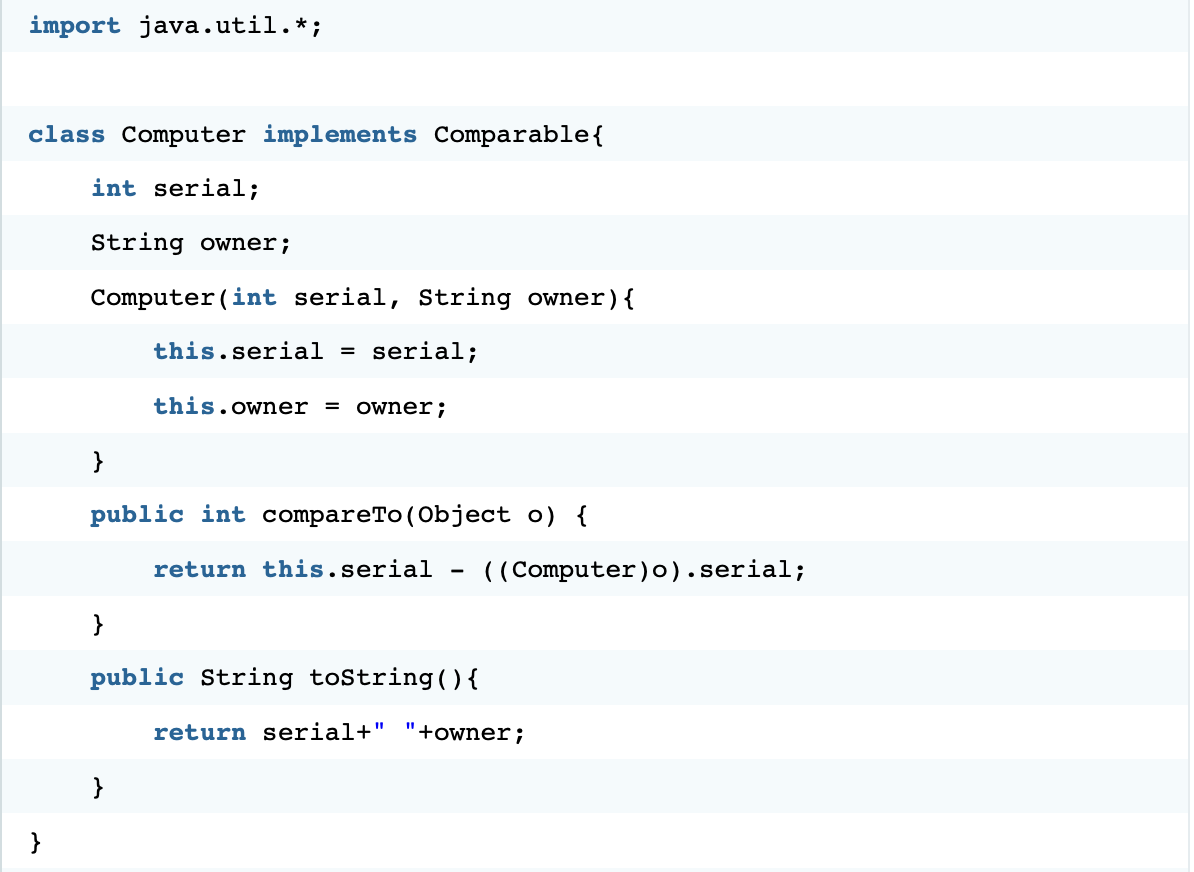

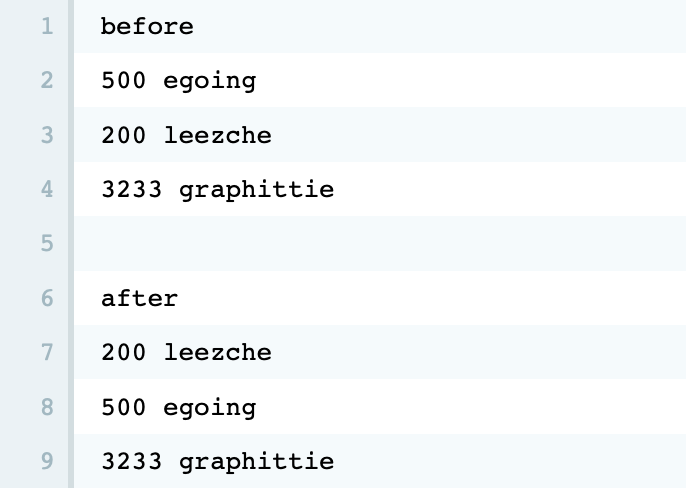
클래스 Collectors는 다양한 클래스 메소드를 가지고 있다. 메소드 sort는 그 중의 하나로 List의 정렬을 수행한다. 다음은 sort의 시그니처다.
public static <T extends Comparable<? super T>> void sort(List<T> list)sort의 인자인 list는 데이터 타입이 List이다. 즉 메소드 sort는 List 형식의 컬렉션을 지원한다는 것을 알 수 있다. 인자 list의 제네릭 <T>는 coparable을 extends 하고 있어야 한다. Comparable은 인터페이스인데 이를 구현하고 있는 클래스는 아래 메소드를 가지고 있어야 한다.
- compareTo(T o)
아래의 메소드는 이러한 제약 조건을 준수하기 위해서 구현한 메소드다.

메소드 sort를 실행하면 내부적으로 compareTo를 실행하고 그 결과에 따라서 객체의 선후 관계를 판별하게 된다. 컬렉션즈 프레임워크는 효율적인 에플리케이션을 구축하기 위해서 매우 중요한 내용이다. 그런데 컬렉션은 단순히 사용법을 이해하는 것으로는 부족하고, 소위 알고리즘이나 자료구조(data structure)라고 불리는 분야에 대한 충분한 이해가 필요하다. 컬렉션즈 프레임워크는 이러한 분야의 성취를 누구나 쉽게 사용할 수 있도록 제공되는 일종의 라이브러리라고 할 수 있기 때문이다.
콜렉션을 마지막으로 생활코딩님의 자바 기초 입문 프로그래밍 강의를 모두 마쳤다. 생활코딩님은 워낙 기초강의로 유명하신분이라 너무 이해도 잘가게끔 초심자의 수준에 맞춰서 설명을 잘해주셨다. 유튜브 강의만 보아도 기본적인 개념들은 거의 다 이해했을정도여서 수강한 느낌으로써 너무 만족하면서 들었다. 1/2 국비학원 수강하기전에 1~2달간 독학하는 입장이었는데 도움이 많이된 것 같다. 지금은 앞으로 약 3주 안되게 시간이 남아있는데 c언어,자바 기초를 마치고 남은시간에 어떤것을 배워볼까 고민중이다. 학원에 가서도 잘 적응하고 잘 수료했으면 좋겠다는 마음뿐이다.. 앞으로의 그날까지 화이팅이다 ~!
'Java' 카테고리의 다른 글
| Java 기초 입문 11일차 (와일드카드, thread, 람다식) (2) | 2022.12.27 |
|---|---|
| Java 자주사용하는 String Class의 생성자와 메소드 (0) | 2022.12.16 |
| Java 이클립스 (eclipse) 단축키 모음 (0) | 2022.12.07 |
| Java 기초 입문 9일차 (제네릭, Arraylist) (0) | 2022.12.07 |
| Java 기초 입문 8일차 (Object, enum, 참조) (0) | 2022.11.27 |