
쌍용 강북 교육센터 국비학원 Day 35일차
데이터 모델링
데이터 모델링이란 정보시스템 구축의 대상이 되는 업무 내용을 분석하여 이해하고 약속된 표기법에 의해 표현하는걸 의미한다. 그리고 이렇게 분석된 모델을 가지고 실제 데이터베이스를 생성하여 개발 및 데이터 관리에 사용된다.
특히 데이터를 추상화한 데이터 모델은 데이터베이스의 골격을 이해하고 그 이해를 바탕으로 SQL문장을 기능과 성능적인 측면에서 효율적으로 작성할 수 있기 때문에 데이터 모델링은 데이터베이스 설계의 핵심 과정이기도 하다.
데이터 모델링 순서 절차
1. 업무 파악 (요구사항 수집 및 분석)
업무 파악은 어떠한 업무를 시작하기 전에 해당하는 업무에 대해서 파악하는 단계이다.
2. 개념적 데이터 모델링
개념적 데이터 모델링은 내가 하고자 하는 일의 데이터 간의 관계를 구상하는 단계이다. 각 개체들과 그들간의 관계를 발견하고 표현하기 위해 ERD 다이어그램을 생성한다.
3. 논리적 데이터 모델링
개념적인 데이터 모델이 완성되면, 구체화된 업무 중심의 데이터 모델을 만들어 내는데, 이것을 논리적인 데이터 모델링이라고한다. 이 단계에서 업무에 대한 Key, 속성, 관계등을 표시하며, 정규화 활동을 수행한다. 정규화는 데이터 모델의 일관성을 확보하고 중복을 제거하여 신뢰성있는 데이터 구조를 얻는데 목적이 있다.
4. 물리적 데이터 모델링
물리적 데이터 모델링은 최종적으로 데이터를 관리할 데이터 베이스를 선택하고, 선택한 데이터 베이스에 실제 테이블을 만드는 작업 을 말한다. 시각적인 구조를 만들었으면 그것을 실제로 SQL 코딩을 통해 완성하는 단계라고 보면 된다
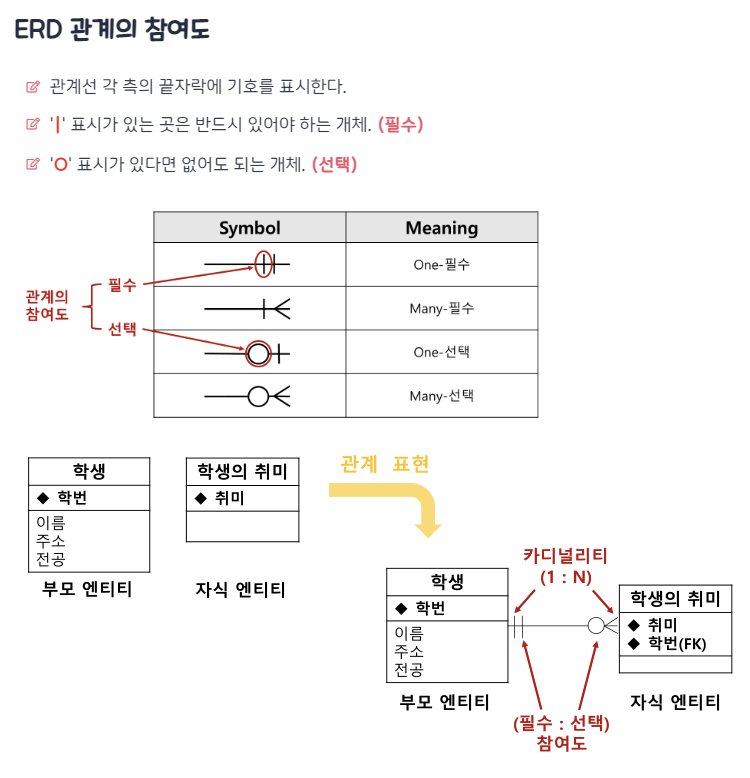
ERD (Entity Relationship Diagram)
ERD는 단어에서 의미하는 그대로 'Entity 개체'와 'Relationship 관계'를 중점적으로 표시하는 데이터베이스 구조를 한 눈에 알아보기 위해 그려놓는 다이어그램이다. 개체 관계도라고도 불리며 요구분석사항에서 얻은 엔티티와 속성들의 관계를 그림으로 표현한 것이다.
각 엔티티 유형들을 만들었으면, 엔티티 끼리 관계가 있는 경우 선을 이어 관계를 맺어야 한다. 엔티티 끼리 관계 선을 그을때 실선으로 그을지 점선으로 그을지 나뉘는데, 두 엔티티 관계에서 부모의 키를 자식에서 PK로 사용하는지 일반 속성으로 사용하지에 따라서 표기가 다르게 된다.
실선으로 그으면 강한 관계를 나타내는 것이며 '식별자 관계'라고 불리우며, 점선으로 그으면 약한 관계를 나타내는 것이며 '비식별자 관계'라고 불리우게 된다.
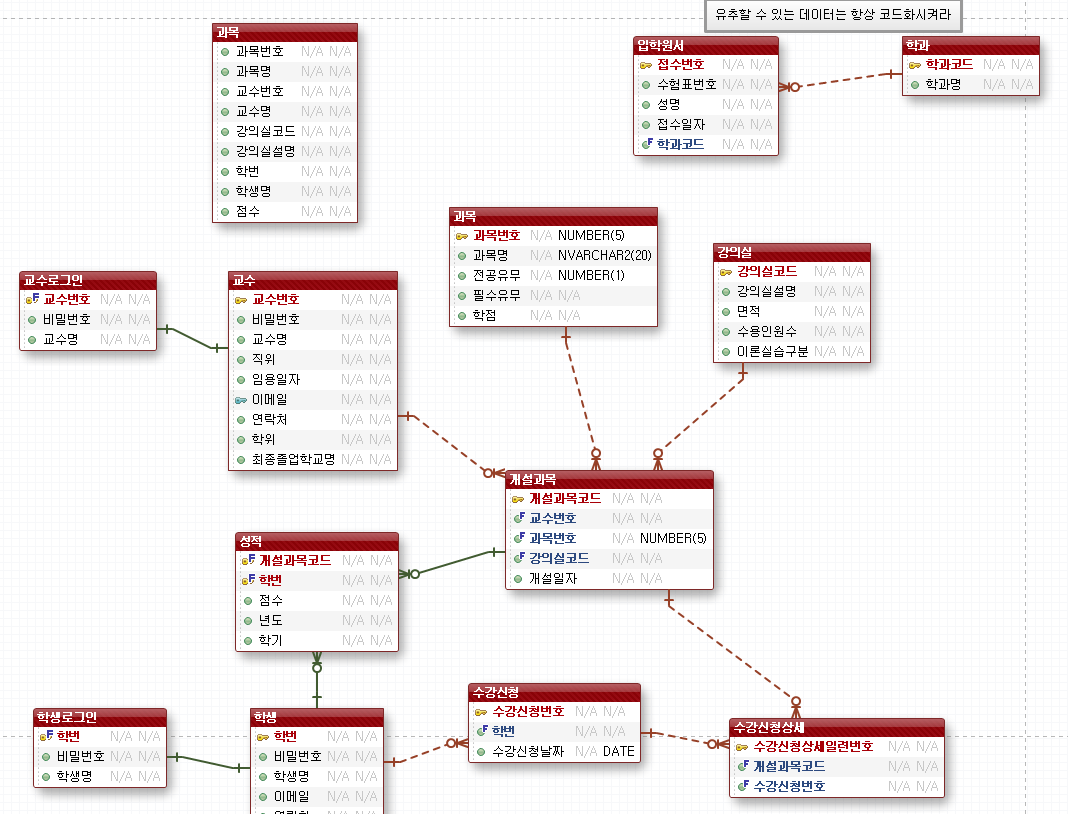
정규화
고유한 식별자를 가지는 모든 개체 (테이블)에 대해 더 이상 분리할 수 없는 상태로 나누는 과정을 말한다. 정규화 과정을 통해 불필요하게 중복된 데이터 제거 작업을 하게 된다. 정규화를 통한 개체의 분리는 관계가 있는 개체간의 참조 관계로 데이터를 유지 보수하게 된다.
정규화 수준을 높이면 데이터량이 줄고 데이터 갱신 속도가 빠르며 같은 자료가 여러 개체에 분산된 것보다 일관성을 유지하기 쉽다. 그러나 관계된 여러 속성을 동시에 조회하는 작업을 수행하기 위해서는 여러 개체를 JOIN 하여 작업해야 하는 어려움이 있을 수 있다.
또 갱신 작업에 있어 여러 개체에 동시에 반영해야 하는 작업의 경우는 명시적으로 트랜잭션 처리해야 하는 수고가 따른다. 따라서 먼저 정규화 과정을 수행하고 수행속도나 프로그램을 구현하기 어려운 경우에는 비정규화(역정규화) 과정으로 문제를 보완하게 된다.
정규화 과정에는 제 1, 2, 3 정규화와 역정규화 과정이 있다. 이러한 정규화 과정을 다시 조인하면 데이터의 손실없이 이전상태로 복구가 가능해야 한다.
제 1 정규화
반복되는 속성들을 다른 개체로 나누어 분리한다. 즉, 같은 성격과 내용의 컬럼이 연속적으로 나타나는 컬럼이 존재할 때 해당 컬럼을 제거하고 기본테이블의 PK를 추가해 새로운 테이블을 생성하고, 기존의 테이블과 1:N 관계를 형성하는 것이다.
제 2 정규화
PK가 여러 키로 구성된 복합키(Composite Primary Key) 로 구성된 경우가 2차 정규화의 대상이 되며, 복합키 전체에 의존하지 않고 복합키의 일부분에만 종속되는 속성들이 존재할 경우 이를 분리하는 것이다. 즉, 복합키로 구성된 식별자를 가진 경우에 식별자의 일부분에 종속적인 속성을 분리한다.
제 3 정규화
식별자 이외의 속성은 식별자가 아닌 다른 속성에 종속적이지 않아야 한다. 식별자 이외의 속성에 종속적인 경우에 분리해 낸다. 즉, PK에 의존하지 않고 일반컬럼에 의존하는 컬럼들을 분리한다.
제 4 정규화
의존적인 (Many to Many) 다 대 다 관계를 제거한다.
역정규화
하나의 표를 성능을 위해서 (다수의 Join을 줄이기 위해) 여러개로 쪼개는 테이블 분리와 마찬가지로 Join을 줄이기 위해 외래키를 통해서 줄이는 방법이 있다.
참고 출처
[DB] 📈 데이터 모델링 개념 & ERD 다이어그램 그리기 💯 총정리
데이터 모델링 이란? 데이터 모델링이란 정보시스템 구축의 대상이 되는 업무 내용을 분석하여 이해하고 약속된 표기법에 의해 표현하는걸 의미한다. 그리고 이렇게 분석된 모델을 가지고 실제
inpa.tistory.com
[DB] 📚 제 1-2-3 정규화 & 역정규화 💯 정리
정규화란? ERD내에서 중복요소를 찾아 제거해 나가는 과정 - 중복된 데이터는 많은 문제를 일으킨다. 3차 정규화 정도만 알면 설계하는데 무리가 없다. - 중복을 최소화 -> 완전히 없애는게 아
inpa.tistory.com
'DB > Oracle' 카테고리의 다른 글
| 쌍용강북교육센터 국비 학원 Day 34일차 Oracle (Oracle INDEX, Plan) (0) | 2023.02.20 |
|---|---|
| 쌍용강북교육센터 국비 학원 Day 33일차 Oracle (Exception 예외처리, Cursor, Package) (0) | 2023.02.17 |
| Oracle 시스템 테이블 명령어정리 (0) | 2023.02.16 |
| 쌍용강북교육센터 국비 학원 Day 32일차 Oracle (PL/SQL문, Procedure, Function, 제어문) (0) | 2023.02.16 |
| 쌍용강북교육센터 국비 학원 Day 31일차 Oracle (ALTER, Foreign key 옵션) (0) | 2023.02.15 |